
你知道贏了世界棋王的AlphaGo是怎麼思考的嗎?這樣看下來人類贏的機會真的不大啊...

看了 AlphaGo 和李世乭九段這 5 場比賽之後,你知道 AlphaGo 是怎麼思考的嗎?
其實,AlphaGo 的“思考”和人類的思考有些相似,所以它的勝利才顯得意義重大。
想要知道 AlphaGo 怎麼下圍棋,簡單瞭解圍棋的規則非常重要。10 分鐘圍棋入門
顧名思義,“圍棋”的要點在於“圍”。圍棋棋盤是 19 × 19 的格狀棋盤,黑子和白字在交叉點上交替落子,哪一方“圍”的地盤大便獲勝。
如何計算“地盤”?每當棋盤上落下一子,便會出現與該子橫或豎相鄰的四個交叉點,這四個點被稱為“氣”,一顆棋子最多擁有四口“氣”,斜方向相鄰的交叉點不是氣。
橫或豎相鄰的同色棋子可以共用“氣”。如果一個字或幾個字周圍所有的氣都被對方棋子佔據,沒有氣的棋子就是死子。
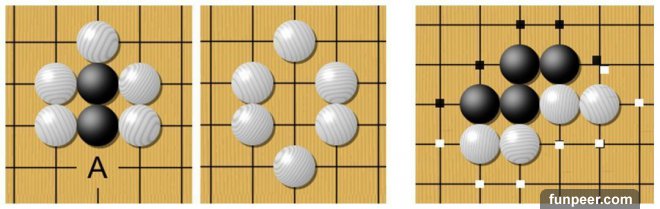
左側圖中 A 點若落下白字,則兩顆黑子沒有氣,被殺死提走。
右側圖中棋子周圍的的點表示氣,雙方棋子可以共用氣。
在這樣的規則要求下,勝負的關鍵便在於如何高效地用棋子佔據更大的地盤,同時還要防止對方將你已經佔據的位置圍死。圍棋開局時一般從靠近邊緣的地方開始落子也是因為相對於棋盤中央,邊緣方便用更少的棋子佔據更大的地方。
圍棋棋盤一共有 361 個落子點,平均分配的話,一方棋子佔據的位置加上活棋圍住的落子點只要超過 180.5 個就會勝利。但先落下第一個子的黑棋佔有優勢,按照中國規則,在計算棋子數量時,黑棋必須減掉 3 又 3/4 子,也就是必須超過 185 子才能獲勝。
有的棋局會在未下完時,便因為對方已經佔據了無法追趕的優勢而認輸。而有的棋局雙方會進行到“收官”的階段,這裡不再展開。
以上,是圍棋的簡單的基礎規則,但因為棋盤很大,圍棋的戰術千變萬化。
AlphaGo 如何思考
說起這個,“窮舉”、“蒙特卡羅樹算法”、“深度學習”等等一大堆術語經常出現。
所謂 “深度學習”,是 AlphaGo 圍棋訓練的第一步,將人類棋譜輸入計算機,學習人類的落子習慣。這種“識別”與人臉識別、圖像分類等搜索技術類似。
第一步:
AlphaGo 會把輸入系統的人類棋譜的每一步進行分拆,棋盤上每個落子以及隨後的應對落子算作一個樣本,AlphaGo 從這些人類棋局中分解出了三千多萬個樣本。
這些樣本集合在一起,能夠識別出每個特定的落子之後,哪一種應對方法的概率最高,這個最高的概率其實就是人類棋手最喜歡的應對方法。
雖然說圍棋“千古無同局”,但是局部來看還是有很多相似的模式反覆出現,AlphaGo 就學會了這些最受歡迎的下法。
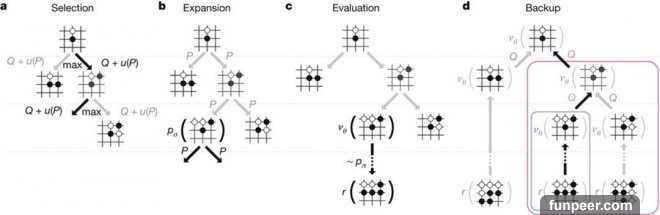
AlphaGo 的蒙特卡洛樹搜索。
第二步:
AlphaGo 的思考結合了蒙特卡羅樹搜索。
假設一個從來都沒下過圍棋的人,用了分身術分成兩個人開始在棋盤上亂下,最終這盤棋也會分出個勝負。第二盤,上一盤贏的那個分身不再完全是亂下了,開始使用贏的那一盤中的一些對應,第三盤棋,第二盤贏的那個分身開始使用第一盤和第二盤中的對應。當第 N 盤棋下完之後,這個始終贏棋的分身就會獲得最有可能獲勝的落子方法。
以上這 N 盤棋就是一步使用蒙特卡羅樹搜索的思考過程,思考結束後的下一個落子,就是被是推演過次數最多,獲勝概率最高的那一步。
AlphaGo 團隊還改進了以上這種傳統的蒙特卡羅樹搜索算法。
上面我們說過的深度神經網絡得出了一套人類棋手概率最高的下法,假設蒙特卡羅樹搜索故事中那個完全不會下棋的人學習了這套下法,那麼之後的“亂下”思考過程的起點就會提高很多。這樣一來,蒙特卡羅樹算法的計算量就減少很多,提高了效率。
第三步:
AlphaGo 自己和自己下棋。 圍棋畢竟變化太多,AlphaGo 需要更多的棋局來學習,於是通過自我對弈產生新的棋局。
AlphaGo 自己和自己下棋,棋力的來源就是第一步通過學習人類棋局得到的落子方法。AlphaGo 左右互搏,自我對弈幾萬盤,就能總結出贏棋概率更高的新下法,接下來再用新下法自我對弈幾萬盤,以此類推,最終得到了一套棋力比最初只學習人類下法厲害很多的新策略。
那用這新的策略和蒙特卡羅樹搜索結合是不是更厲害呢?答案卻是否。
因為使用概率來訓練的這種策略會讓下法高度集中,變化太少,而蒙特卡羅樹搜索需要更多的變化才更有效。

AlphaGo 在與樊麾對決時的局面評估。
第四步:局面評估。這也是 AlphaGo 最厲害的地方是,它可以像人類一樣在比賽過程中估計局面的優劣,這樣纔有第四局它判斷獲勝機率太小,選擇中盤認輸。
當一盤棋開始的時候,AlphaGo 先用第一步訓練的下法下若干步,然後亂下一步,接著用第三步自我對弈訓練產生的更厲害的下法下完整盤棋,然後對結果做一個評估,評估出“亂下”的那步棋造成的局面是好是壞。
AlphaGo 可以在一步的思考中亂下很多次,總有一次能匹配到真實對下棋的狀況。而對這一步亂下以及後續結果的評估,就是對當前局面的判斷。圍棋 AI 和其它棋類 AI 區別很大
大家對戰勝卡斯帕羅夫的“深藍”有一些誤解。深藍並不是單純的“窮舉”,通過計算所有的可能性來實現勝利。深藍的算力約為每秒 2 億步棋,想要窮盡國際象棋十的四十五次方這個級別的可能性需要十的二十九次方年的時間,這顯然不可能。
深藍內置了數百萬人類國際象棋的開局庫,這部分計算可以省掉,同時深藍也不是算出所有可能的步法,而是推算 12 步左右,而人類的國際象棋大師大約能夠推算 10 步,勝負就在這其中產生。
AlphaGo 每秒鐘可以計算幾百萬步棋,通過大量學習人類棋局,用這些經驗自我對弈產生新的經驗,用這些新經驗來下棋,再利用蒙特卡羅樹搜索產生下一步對應的下法,配合“亂下”產生的對局面的評估,就是 AlphaGo 戰勝人類頂尖棋手的祕密。
[圖擷取自網路,如有疑問請私訊]
|
本篇 |
不想錯過? 請追蹤FB專頁! |
| 喜歡這篇嗎?快分享吧! |








相關文章






一刻館









