
阿里50億參數AI畫畫模型火了!圖像拆分再自由重組,創造力飛升
AI畫畫通用模型,新增一員大將!由阿里達摩院副院長 周靖人等人打造的可控擴散模型 Composer,一經發布就小火了一把。

這個模型由 50億參數訓練而來,和Stable Diffusion原理不同。
它 更進一步把訓練圖像拆解成了多個元素,然后基于這些元素訓練擴散模型,讓它們能夠靈活組合。
由此一來,模型的創造能力就比僅基于圖像大很多。
如果有100張能拆分成8個元素的圖像,那麼就能生成一個數量為100的8次方的結果組合。

網友們看了紛紛表示,AI畫畫發展速度也太快了!
團隊表示,模型的訓練和推理代碼都在路上了。
有限手段的無限使用該框架的核心思想是 組合性(compositionality),模型名字就叫做 Composer。
觀察到現下很多AI畫畫模型,在細節的可控性上還沒有做到很好,比如準確改變顏色、形狀等。
研究團隊認為,想要實現圖像的可控生成,不能依賴于對模型的調節,重點應該放在組合性上,這種方式可以將圖像的創造力提升到指數級。
引用語言學大師諾姆·喬姆斯基的經典語錄來解釋模型,就是:
有限手段的無限使用。
具體來看,該模型就是將每個訓練圖像拆解成一系列基礎元素,如蒙版圖、草稿圖、文字描述等,用它們來訓練一個擴散模型。

然后讓這些被拆分的元素,在推理階段靈活組合,生成大量新的圖像輸出。

它可以 支持多種形式作為輸入。比如文字描述作為全局信息,深度圖和草圖作為局部引導,顏色直方圖為低級細節等。
在保證生成圖像可控的基礎上,作為一個通用框架,該模型還能不用再訓練就可以完成大量經典生成任務。
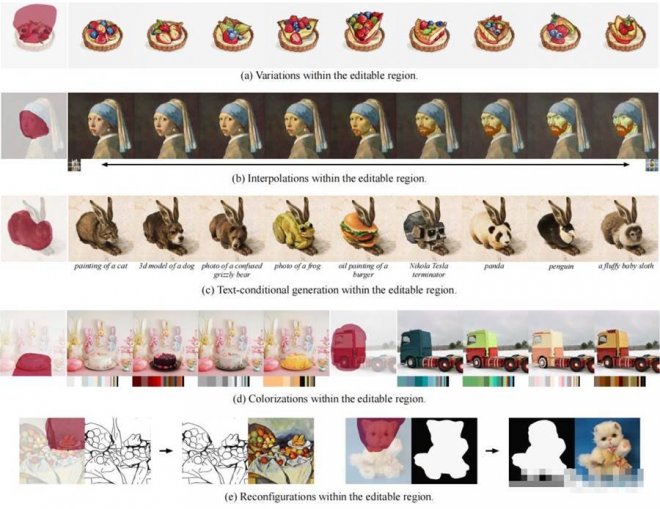
舉例來看,圖(a)中,最左邊的是原圖,后面4個是通過對Composer不同子集的表示進行調節而生成的新結果。
圖(b)展示的是圖像插值的結果。

圖像重構的話是醬嬸兒的,Composer能夠簡單地改變圖像表示來重新配置圖像,比如草稿圖和分割圖。

還有對圖像的特定部分進行編輯。
比如給蛋糕派換口味、把珍珠耳環少女的臉換成梵高、讓兔子長一張貓熊臉等。
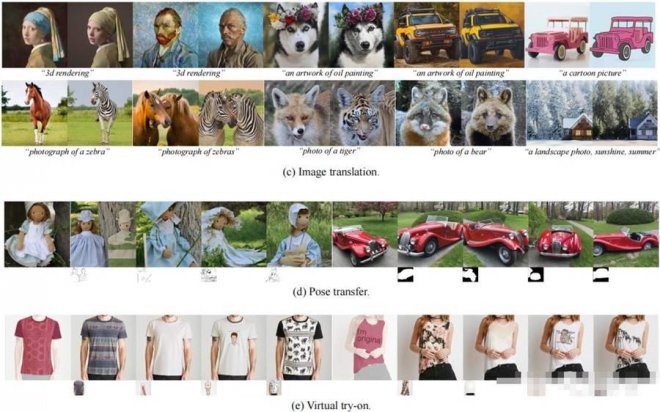
比較經典的圖像生成任務也能挑戰,而且無需再訓練。

團隊表示,現有成果還存在一定局限性,比如在單一條件輸入的情況下,生成效果不是很好。以及輸入不同語義的圖像和文本嵌入時,生成結果會降低對文本嵌入的權重。
而針對AI畫畫模型都需要面對的風險問題,團隊表示為避免被濫用,他們會在公開模型前先創建一個過濾版本。
達摩院副院長帶隊該研究由阿里及螞蟻團隊完成。

通訊作者為 周靖人。

他現任阿里達摩院副院長、阿里云智能CTO,是IEEE Fellow。
2004年于哥倫比亞大學獲得計算機博士學位,后加入微軟擔任研發合伙人。
2015年,周靖人加入阿里巴巴集團,先后負責過達摩院智能計算實驗室、大數據智能計算平台、搜索推薦事業部等。
論文一作 Huang Lianghua同樣來自達摩院,研究方向為擴大模型規模和數據來表示學習和內容生成。
[圖擷取自網路,如有疑問請私訊]
|
本篇 |
不想錯過? 請追蹤FB專頁! |
| 喜歡這篇嗎?快分享吧! |








相關文章






科普解密








