ChatGPT開源平替來了,開箱即用!前OpenAI團隊打造,GitHub800星
ChatGPT的開源平替來了,源代碼、模型權重和訓練數據集全部公開。它叫 OpenChatKit,由前OpenAI研究員共同打造。
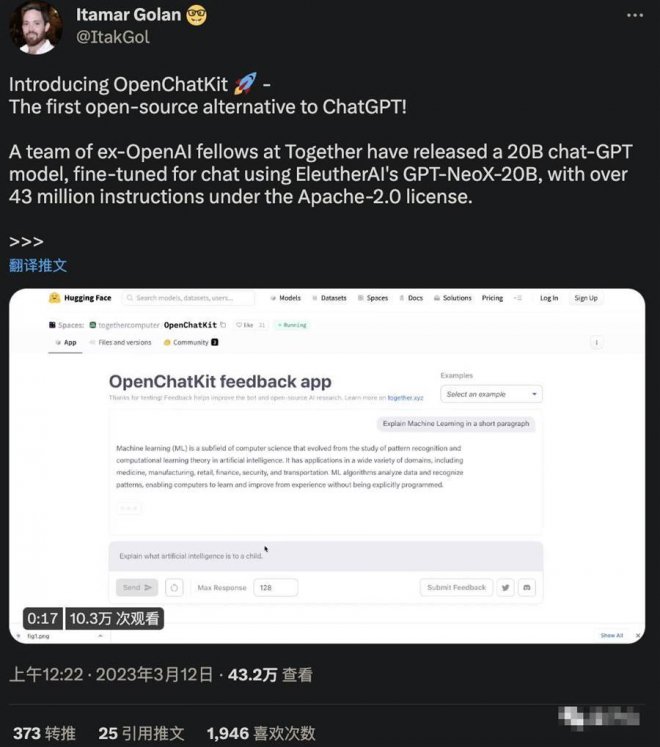
效果是這樣兒的:
可以用簡單的語言解釋機器學習的概念,也可以回答測試者提出的第二個小問題。
視訊加載中...
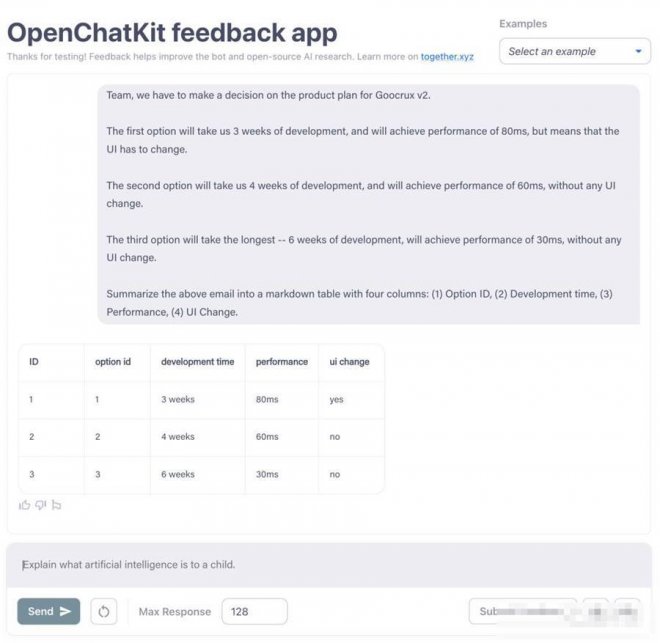
信息提取也難不倒它,比如將一大段計劃用表格表示。
據悉,OpenChatKit一共包含200億參數,在EleutherAI的GPT-NeoX-20B(GPT-3開源替代品)上進行了微調,還可以連接其它API或數據源進行檢索等等。
這不,GitHub剛剛上線,就已經獲得了800+標星。

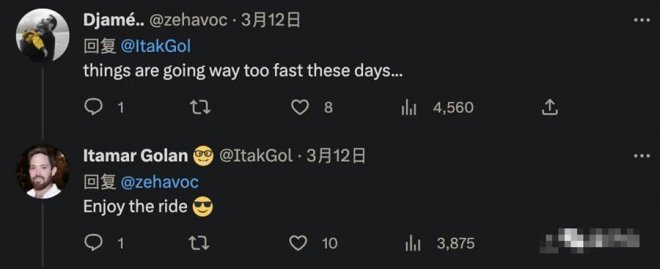
有網友感嘆「事情進展得也太快了吧」,作者則回應:
安全帶系緊,享受「飆車」吧。
來看看它具體怎麼玩?
OpenChatKit,你的平替ChatGPT據介紹,OpenChatKit一共包含4個基本組件:
1、一個指令調優的大型語言模型。
用EleutherAI的GPT-NoX-20B對聊天功能進行了微調,后者在carbon-negative計算上具有4300萬條指令。
調整重點是多輪對話、問答、分類、提取和摘要等幾個任務。
2、定制配方(recipe)。
用來幫助微調模型使其能夠為特定任務提供高精度的結果,只需要準備自己的數據集。
3、一個可擴展的檢索系統。
可以讓你在推理時從文檔存儲庫、API或其他實時更新信息源添加信息。

4、一個由GPT-JT-6B微調而成的調節模型(moderation model)。可以過濾模型對一些問題的響應。
這樣的OpenChatKit可以為各種應用程序創建專用和通用的聊天機器人。

在GitHub上的倉庫,你可以找到它的訓練代碼、測試推理代碼以及通過檢索增強模型的代碼。
具體如何使用?
首先,在開始之前,安好PyTorch和其他依賴項。
先從作者團隊的網站(Together)安裝Miniconda,然后用此repo根目錄下的environment.yml文件創建一個名為OpenChatKit的環境。
由于repo使用Git LFS來管理文件,所以還需要按照他們網站上的說明進行安裝,然后運行git lfs install。
接著,關于 預訓練權重。
GPT-NeoXT-Chat-Base-20B是GPT NeoX的200億參數變體,它在會話數據集上進行了微調。
作者在Huggingface上的GPT-Next-Chat-Base-20B發布了預訓練權重。
數據集方面,OpenChatKit模型是在LAION、Together和Ontocord.ai共同構建的OIG數據集上訓練的。
同樣,從Huggingface下載數據集,然后在repo的根目錄運行以下命令就行:
python data/OIG/prepare.py。
(你也可以貢獻新的數據來改善模型效果~)
然后就可以 預訓練基礎模型了。
方法是在根目錄用以下命令下載GPT-NeoX-20B模型:
python pretrained/GPT-NeoX-20B/prepare.py。
它的權重放在pretrained/GPT-NeoX-20B/EleutherAI_gpt-neox-20b目錄中。
下載好之后,執行bash training/finetune_GPT-NeoXT-Chat-Base-20B.sh腳本,開始配置和訓練。
訓練會啟動8個進程,管道并行度為8,數據并行度為1。Checkpoints則將保存到repo根目錄的model_ckpts目錄中。
在 推理之前,請務必將模型轉換為Hugginface格式。
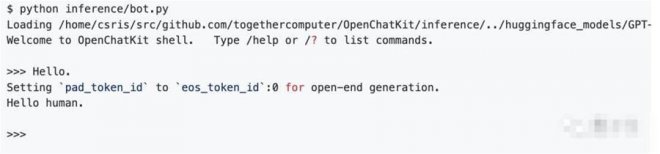
為了幫助你測試模型,作者也在這里提供了一個簡單的測試命令行工具來進行交互,執行命令:
python inference/bot.py。
默認情況下,腳本會在目錄下加載名為GPT-NeoXT-Chat-Base-20B model的模型,但我們可以通過—model進行改變。
都弄好之后,在提示符處輸入文本,模型就會回復了。
最后,作者還提供了一個用維基百科進行擴展搜索的例子,操作也比較簡單,感興趣的同學可以自行查看。
[圖擷取自網路,如有疑問請私訊]
|
本篇 |
不想錯過? 請追蹤FB專頁! |
| 喜歡這篇嗎?快分享吧! |








相關文章






科普解密